-1.png?width=450&height=100&name=Untitled%20design%20(34)-1.png "DorothyAI")
If you’ve talked to me recently, I likely told you about our efforts to build the ultimate Freedom-To-Operate (FTO) search engine, Dorothy FREEDOMTM (pronounced Braveheart style, obviously).

DorothyAI CEO, Curt Wadsworth, will not skip an opportunity to feature Braveheart.
Efforts to bring Dorothy FREEDOMTM to fruition began this week with a visit to the IBM Watson Discovery office in Pittsburgh and continued with yours truly defining the parts of claims, relationships between parts of claims and elements, color coding issued claims, and drawing arrows to various elements and parts. It’s not glamorous, but frankly, I’d rather be doing that right now. Not so much because I like it, but because the world needs my claim construction expertise encoded in a machine learning model very badly.
From a machine learning perspective, claims should be fertile ground for modeling. Claims have a specific pattern that is universally followed: (i) preamble, (ii) transitional phrase, (iii) description of the invention. Articles (a, an, the) have specific meanings, and the elements that is modified by phrases that add limitations are typically easily identifiable. I should be able to quickly annotate a group of claims and build a machine learning model that properly parses claims. Or so I thought.
Watson Knowledge Studio makes the annotation process relatively easy. I uploaded a group of claims describing medical devices, defined entity types and relation types, and labeled the parts of some claims. Knowledge Studio uses the annotated claims to build a machine learning model and tests the model. Easy peasy! In reality, I defined entity types, labeled claims, realized I could do better, started over, redefined entity types, labeled claims, added relation types (backwards), and started over. There’s a learning curve. You get the picture. Eventually, I got it.
Claims are more complicated than you might think.
The universal pattern is actually quite universal. Every claim I’ve analyzed begins with a preamble, which defines the type of claim (device, article of manufacture, compound, composition, or method). The preamble is followed by a transitional phrase (comprising or having, usually), and a description of the invention follows the transitional phrase.
However, even the simplest aspects of claim construction can be complicated. For example, the use (or overuse) of transitional phrases can make it difficult to determine where the preamble ends and the description of the invention begins. Under U.S. law, a “Jepson claim” includes a description of the prior art in the preamble with a specific point of novelty described after the transitional phrase. Distinguishing a Jepson claim from a “normal” claim can be difficult for a seasoned patent attorney, particularly when the first transitional phrase used in the claim is “having” and “comprising” is used later.
Matching descriptions and “wherein” clauses with their intended element or the invention as a whole, and defining how they modify the element or invention is a challenge. In some cases, additional elements are added to the invention in a description or “wherein” clause adding further complexity to the claim. Here’s a screenshot of part of an annotated claim to give you an idea of the various parts and how they are related:
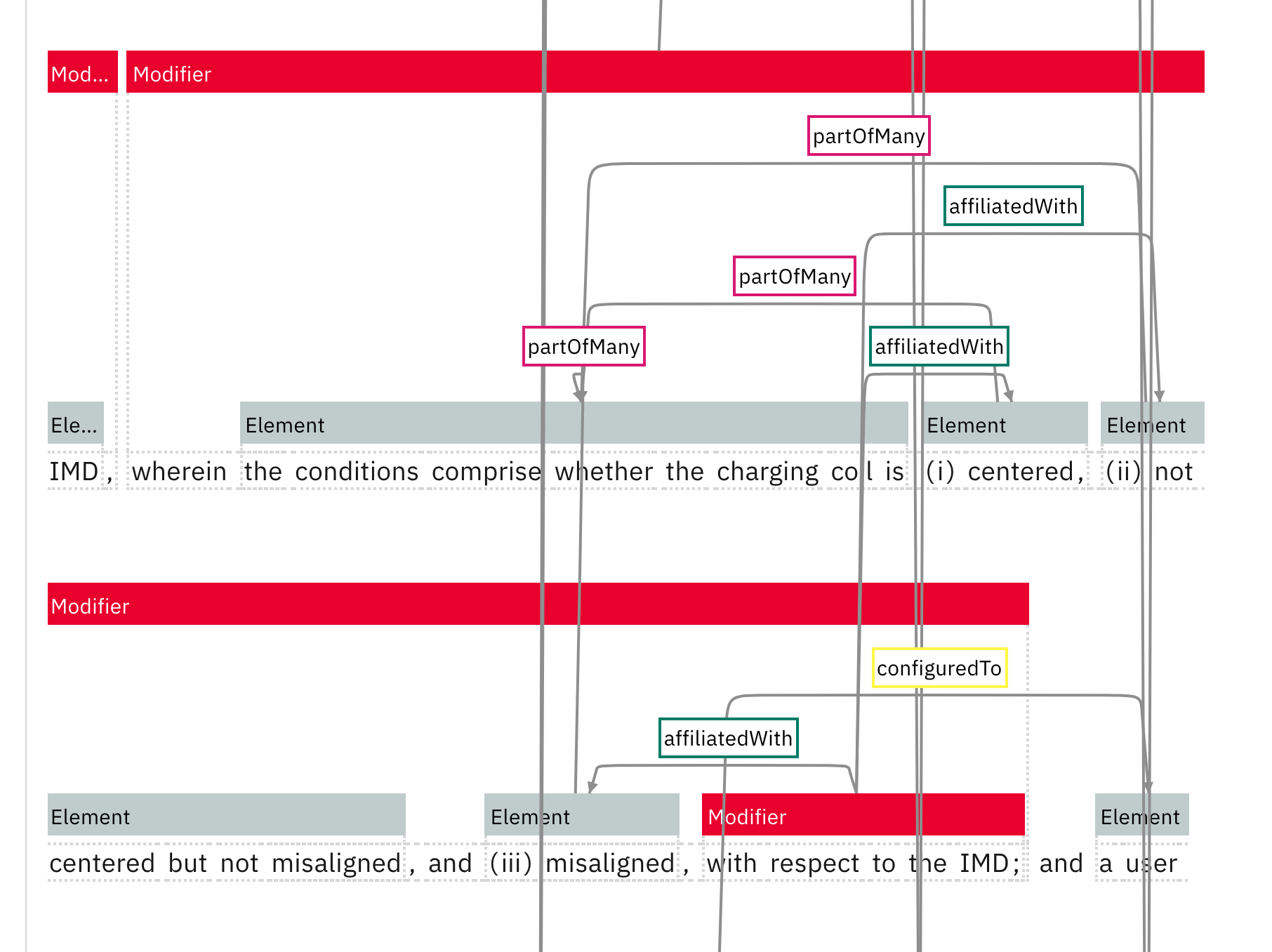
The point of this exercise is to import as much of my knowledge of claim construction to the machine learning model as possible. This is supervised learning. Without human input, the model will identify these relationships on its own. This is unsupervised learning, which may or may not result in a model that parses claims properly.
Our hope is that Knowledge Studio and other components of Watson Discovery will help us build a database of indexed claims that, we can query using our Natural Language Processing search models, creating the ultimate FTO engine Dorothy FREEDOMTM.
